
Comprender los retos de la IA Generativa en la era de la web abierta. Cómo la tecnología GenAI puede moldear el discurso público y la calidad de la información.
Se ha hablado mucho de las extraordinarias oportunidades de la IA Generativa (GenAI), y algunos de nosotros también hemos sido muy explícitos sobre los riesgos asociados al uso de esta tecnología transformadora.
El auge de la GenAI plantea retos importantes para la calidad de la información, el discurso público y la web abierta en general. El poder de la GenAI para predecir y personalizar contenidos puede utilizarse fácilmente para manipular lo que vemos y con lo que interactuamos.
Cómo el sector SEO puede aprovechar y mejorar la IA generativa
Los motores de búsqueda de IA generativa están contribuyendo al ruido general, y en lugar de ayudar a la gente a encontrar la verdad y forjarse opiniones imparciales, tienden (al menos en su implementación actual) a promover la eficiencia por encima de la precisión, como pone de relieve un estudio reciente de Jigsaw, una unidad dentro de Google.
A pesar de la exageración que rodea a las fiestas de los caimanes del SEO y a los duendes de los contenidos, nuestra generación de profesionales del marketing y del SEO lleva años trabajando por un entorno web más positivo.
Hemos cambiado el enfoque del marketing, que ha pasado de manipular a las audiencias a dotarlas de conocimientos que, en última instancia, ayudan a las partes interesadas a tomar decisiones con conocimiento de causa.
La creación de una ontología para SEO es un esfuerzo liderado por la comunidad que se alinea perfectamente con nuestra misión actual de dar forma, mejorar y proporcionar direcciones que realmente hagan avanzar la interacción humano-GenAI, preservando al mismo tiempo a los creadores de contenidos y a la Web como un recurso compartido para el conocimiento y la prosperidad.
Breve descripción de las prácticas tradicionales de SEO y su evolución
Las prácticas tradicionales de SEO a principios de la década de 2010 se centraban en gran medida en la optimización de palabras clave. Esto incluía tácticas como el relleno de palabras clave, los esquemas de enlaces y la creación de contenidos de baja calidad destinados principalmente a los motores de búsqueda.
Desde entonces, el SEO ha cambiado hacia un enfoque más centrado en el usuario. La actualización Hummingbird (2013) marcó la transición de Google hacia la búsqueda semántica, cuyo objetivo es comprender el contexto y la intención detrás de las consultas de búsqueda en lugar de solo las palabras clave.
Esta evolución ha llevado a los profesionales del SEO a centrarse más en grupos temáticos y entidades que en palabras clave individuales, mejorando la capacidad de los contenidos para responder a múltiples consultas de los usuarios.
Las entidades son elementos distintos, como personas, lugares o cosas, que los motores de búsqueda reconocen y entienden como conceptos individuales.
Mediante la creación de contenidos que definan claramente estas entidades y se relacionen con ellas, las organizaciones pueden mejorar su visibilidad en diversas plataformas, no sólo en las búsquedas web tradicionales.
Este enfoque enlaza con el concepto más amplio de SEO basado en entidades, que garantiza que la entidad asociada a una empresa esté bien definida en toda la web.
Del contenido estático a los datos semánticos
En la actualidad, los contenidos estáticos que buscan un buen posicionamiento en los motores de búsqueda se transforman y enriquecen constantemente con datos semánticos.
Se trata de estructurar la información de modo que sea comprensible no sólo para las personas, sino también para las máquinas.
Esta transición es crucial para potenciar los gráficos de conocimiento y las respuestas generadas por IA, como las ofrecidas por AIO de Google o Bing Copilot, que proporcionan a los usuarios respuestas directas y enlaces a sitios web relevantes.
A medida que avanzamos, crece la importancia de alinear los contenidos con la búsqueda semántica y la comprensión de entidades.
Se anima a las empresas a estructurar sus contenidos de forma que sean fácilmente comprensibles e indexados por los motores de búsqueda, mejorando así la visibilidad en múltiples superficies digitales, como las búsquedas por voz y visuales.
El uso de la IA y la automatización en estos procesos es cada vez mayor, lo que permite interacciones más dinámicas con los contenidos y experiencias de usuario personalizadas.
Nos guste o no, la IA nos ayudará a comparar opciones más rápidamente, realizar búsquedas profundas sin esfuerzo y efectuar transacciones sin pasar por un sitio web.
Automatización e IA en SEO
El futuro del SEO es prometedor. Se prevé que el tamaño del mercado de servicios SEO crezca de 75.130 millones de dólares en 2023 a 88.910 millones en 2024 -una asombrosa CAGR del 18,3% (según The Business Research Company)- a medida que se adapte para incorporar tecnologías semánticas y de IA fiables.
Estas innovaciones favorecen la creación de entornos web más dinámicos y receptivos que se adaptan mejor a las necesidades y comportamientos de los usuarios.
Sin embargo, el camino no ha estado exento de dificultades, especialmente en las grandes empresas. Implantar soluciones de IA que sean a la vez explicables y estratégicamente alineadas con los objetivos de la organización ha sido una tarea compleja.
Construir una IA eficaz implica agregar datos relevantes y transformarlos en conocimiento procesable.
Esto diferencia a una organización de los competidores que utilizan modelos lingüísticos o patrones de desarrollo similares, como los agentes conversacionales o los copilotos de generación aumentada por recuperación, y mejora su propuesta de valor única.
Introducción a la SEOntología y su importancia en el panorama digital actual
¿Qué es una ontología para SEO en términos sencillos?
Imagine una ontología como un gigantesco manual de instrucciones para describir conceptos específicos. En el mundo del SEO, manejamos mucha jerga, ¿verdad? Topicalidad, backlinks, E-E-A-T, datos estructurados… ¡puede resultar confuso!
Una ontología para SEO es un acuerdo gigante sobre lo que significan todos esos términos. Es como un diccionario compartido, pero aún mejor. Este diccionario no sólo define cada palabra. También muestra cómo se conectan y funcionan entre sí. Así, «consultas» podría estar vinculado a «intención de búsqueda» y «páginas web», explicando cómo todos ellos desempeñan un papel en el éxito de una estrategia SEO.
Imagínatelo como desenredar un gran nudo de prácticas y términos SEO y convertirlos en un mapa claro y organizado: ¡ese es el poder de la ontología!
Aunque Schema.org es un ejemplo fantástico de vocabulario enlazado, se centra en definir atributos específicos de una página web, como el tipo de contenido o el autor. Es excelente para ayudar a los motores de búsqueda a entender nuestro contenido. Pero, ¿qué ocurre con la creación de enlaces entre páginas web?
¿Y la consulta más frecuente en una página web? Estos son elementos cruciales en nuestro trabajo diario, y una ontología puede ser un marco compartido para ellos también. Piensa en ella como un patio de recreo en el que todo el mundo es bienvenido a contribuir en GitHub, de forma similar a cómo evoluciona el vocabulario de Schema.org.
La idea de una ontología para SEO es aumentar Schema.org con una extensión similar a lo que hizo GS1 al crear su vocabulario. Entonces, ¿se trata de una base de datos? ¿Un marco de colaboración o qué? Es todas estas cosas juntas. La ontología SEO funciona como una base de conocimientos colaborativa.
Actúa como un eje central en el que todos pueden aportar su experiencia para definir conceptos clave de SEO y cómo se interrelacionan. Al establecer una comprensión compartida de estos conceptos, la comunidad SEO desempeña un papel crucial en la configuración del futuro de las experiencias de IA centradas en el ser humano.
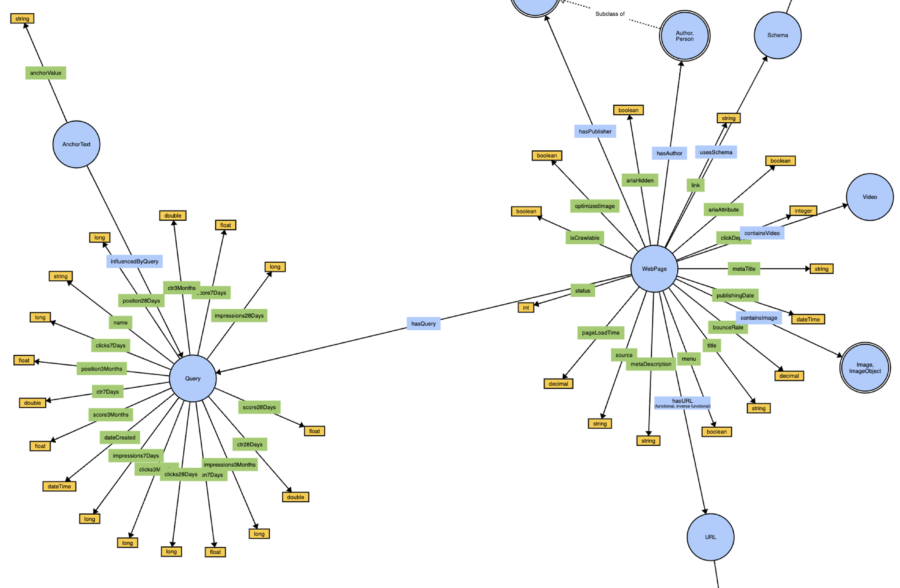
Captura de pantalla de WebVowl, agosto de 2024SEOntología – una instantánea (ver una visualización interactiva aquí).
El reto de la interoperabilidad de datos en el sector SEO
Empecemos por el principio y repasemos las ventajas de una ontología compartida con un ejemplo práctico (he aquí una diapositiva extraída de la presentación de Emilija Gjorgjevska en el ZagrebSEOSummit de este año).
Imagina que tu colega Valentina utiliza una extensión de Chrome para exportar datos de Google Search Console (GSC) a Google Sheets. Los datos incluyen columnas como «ID», «Consulta» e «Impresiones» (como se muestra a la izquierda). Pero Valentina colabora con Jan, que está construyendo una capa de negocio utilizando los mismos datos de GSC. El problema es el siguiente: Jan utiliza una convención de nomenclatura diferente («UID», «Name», «Impressionen» y «Klicks»).
Ahora, amplíe este escenario. Imagina que trabajas con n socios de datos, herramientas y miembros de equipo diferentes, todos ellos utilizando varios idiomas. El esfuerzo de traducir y reconciliar constantemente estas diferentes convenciones de nomenclatura se convierte en un gran obstáculo para la colaboración eficaz de datos.
Se pierde mucho valor al intentar que todo funcione a la vez. Aquí es donde entra en juego la ontología SEO. Es un lenguaje común que proporciona un nombre compartido para el mismo concepto en diferentes herramientas, socios e idiomas.
Al eliminar la necesidad de traducción y conciliación constantes, una ontología SEO agiliza la colaboración de datos y libera el verdadero valor de sus datos.
La génesis de la SEOntología
En el último año, hemos sido testigos de la proliferación de agentes de IA y de la amplia adopción de la Generación Aumentada de Recuperación (RAG) en todas sus diferentes formas (Modular, Graph RAG, etc.).
La RAG representa un importante salto adelante en la tecnología de la IA, ya que aborda una limitación clave de los grandes modelos lingüísticos (LLM) tradicionales al permitirles acceder a conocimientos externos.
Tradicionalmente, los LLM son como bibliotecas con un solo libro, limitados por sus datos de formación. El GAR desbloquea una amplia red de recursos, lo que permite a los LLM ofrecer respuestas más completas y precisas.
Las GAR mejoran la precisión de los hechos y la comprensión del contexto, reduciendo potencialmente los sesgos. Aunque prometedoras, las GAR se enfrentan a retos en materia de seguridad de datos, precisión, escalabilidad e integración, especialmente en el sector empresarial.
Para que su aplicación tenga éxito, el GAR requiere datos estructurados de alta calidad a los que se pueda acceder y ampliar fácilmente.
Hemos sido de los primeros en experimentar con agentes de IA y RAG impulsados por el Knowledge Graph en el contexto de la creación de contenidos y la automatización SEO.
Los grafos de conocimiento (KG) ganan impulso en el desarrollo de los GAR
GraphRAG de Microsoft y soluciones como LlamaIndex lo demuestran. El RAG básico tiene dificultades para conectar información de fuentes dispares, lo que dificulta las tareas que requieren una comprensión holística de grandes conjuntos de datos.
Los enfoques RAG potenciados por KG, como el que ofrece LlamaIndex junto con WordLift, abordan esta cuestión creando un gráfico de conocimiento a partir de los datos del sitio web y utilizándolo junto con el LLM para mejorar la precisión de las respuestas, sobre todo en el caso de las preguntas complejas.

Imagen del autor, agosto de 2024
Llevamos más de un año probando flujos de trabajo con clientes de distintos sectores verticales.
Desde la búsqueda de palabras clave para grandes equipos editoriales hasta la generación de preguntas y respuestas para sitios web de comercio electrónico, pasando por la agrupación de contenidos, la redacción del esquema de un boletín o la renovación de artículos existentes, hemos estado probando diferentes estrategias y hemos aprendido algunas cosas por el camino:
1. El GAR está sobrevalorado
Es simplemente uno de los muchos patrones de desarrollo que consiguen un objetivo de mayor complejidad. Un RAG (o Graph RAG) está pensado para ayudarle a ahorrar tiempo a la hora de encontrar una respuesta. Es brillante, pero no resuelve ninguna de las tareas de marketing que un equipo debe manejar a diario. Hay que centrarse en los datos y en el modelo de datos.
Aunque hay GAR buenas y GAR malas, la clave de la diferenciación suele estar representada por la parte «R» de la ecuación: la recuperación. Principalmente, la recuperación diferencia una demostración de fantasía de una aplicación en el mundo real, y detrás de un buen GAR, siempre hay buenos datos. Los datos, sin embargo, no son cualquier tipo de datos (o datos gráficos).
Se construye en torno a un modelo de datos coherente que tenga sentido para su caso de uso. Si se crea un motor de búsqueda de vinos, hay que obtener el mejor conjunto de datos y modelar los datos en torno a las características en las que se basará un usuario cuando busque información.
Así pues, los datos son importantes, pero el modelo de datos lo es aún más. Si estás construyendo un agente de IA que tiene que hacer cosas en tu ecosistema de marketing, debes modelar los datos en consecuencia. Quieres representar la esencia de las páginas web y los activos de contenido.
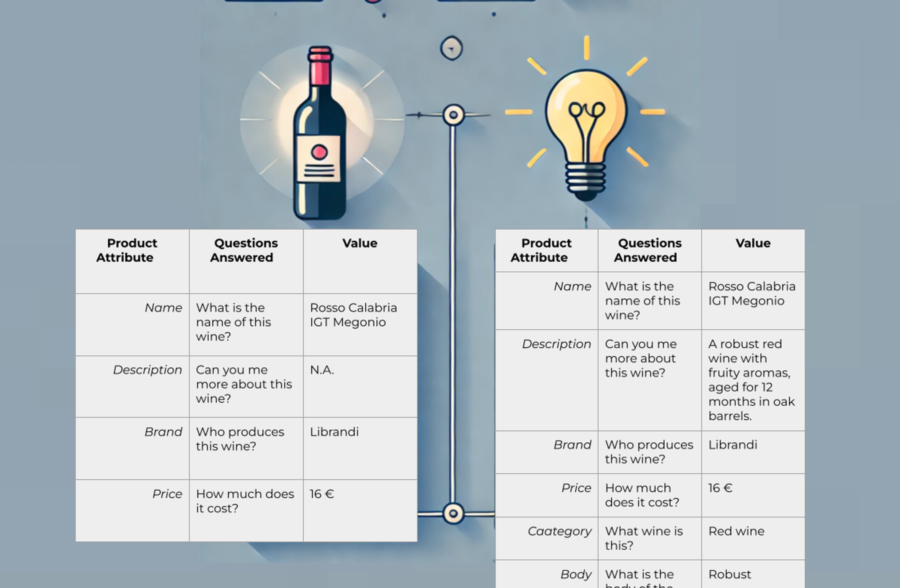
Imagen del autor, agosto de 2024
2. No a todo el mundo se le da bien preguntar
Expresar una tarea por escrito es difícil. La ingeniería de prompts va a toda velocidad hacia la automatización (aquí está mi artículo sobre cómo pasar del prompting a la programación de prompts para SEO), ya que solo unos pocos expertos pueden escribir el prompt que nos lleve al resultado esperado.
Esto plantea varios retos para el diseño de la experiencia de usuario de los agentes autónomos. Jakon Nielsen ha sido muy explícito sobre el impacto negativo de los avisos en la usabilidad de las aplicaciones de IA:
«Uno de los principales inconvenientes de usabilidad es que los usuarios deben ser muy elocuentes para escribir el texto en prosa requerido para las indicaciones».
Incluso en los países occidentales ricos, las estadísticas de Nielsen indican que sólo el 10% de la población puede utilizar plenamente la IA.
| Sugerencia sencilla para utilizar la cadena de pensamiento (CdT) | Pregunta más sofisticada que combina el grafo de pensamiento y la cadena de conocimiento |
| «Explica paso a paso cómo calcular el área de una circunferencia de 5 unidades de radio». | «Utilizando las técnicas del Gráfico del Pensamiento (GpP) y de la Cadena de Conocimientos (CdC), proporcione una explicación completa de cómo calcular el área de un círculo con un radio de 5 unidades. Su respuesta debe: Comenzar con un diagrama GoT que represente visualmente los conceptos clave y sus relaciones, incluyendo: Círculo Radio Área Pi (π) Fórmula para el área de un círculo Seguir el diagrama GoT con un desglose CoK que: a) Defina cada concepto en el diagrama b) Explique las relaciones entre estos conceptos c) Proporcione el contexto histórico para el desarrollo de la fórmula del área de un círculo Presentar un proceso de cálculo paso a paso, que incluya: a) Enunciar la fórmula para el área de un círculo b) Explicar el papel de cada componente en la fórmula c) Mostrar la sustitución de valores d) Realizar el cálculo e) Redondear el resultado a un número adecuado de decimales Concluir con aplicaciones prácticas de este cálculo en situaciones reales. A lo largo de su explicación, asegúrese de que cada paso sigue lógicamente al anterior, creando una clara cadena de razonamiento desde los conceptos básicos hasta el resultado final.» Esta indicación mejorada incorpora el GoT al solicitar una representación visual de los conceptos y sus relaciones. También emplea el CoK al pedir definiciones, contexto histórico y conexiones entre ideas. El desglose paso a paso y las aplicaciones al mundo real mejoran aún más la profundidad y el sentido práctico de la explicación». Traducción realizada con la versión gratuita del traductor www.DeepL.com/Translator |
3. Sugerencia sencilla para utilizar la cadena de pensamiento (CdT)
La lección aprendida es que debemos elaborar procedimientos normalizados de trabajo (PNT) detallados y protocolos escritos que describan los pasos y procesos para garantizar la coherencia, calidad y eficacia en la ejecución de determinadas tareas de optimización.
Podemos ver pruebas empíricas del auge de bibliotecas puntuales como la que se ofrece a los usuarios de modelos antrópicos o el increíble éxito de proyectos como AIPRM.
En realidad, aprendimos que lo que crea valor empresarial es una serie de pasos ci que ayudan al usuario a traducir el contexto en el que navega en una definición coherente de la tarea.
Podemos empezar a imaginar las tareas de marketing como la realización de la investigación de palabras clave como un procedimiento operativo estándar que puede guiar al usuario a través de múltiples pasos (aquí es cómo pretendemos que el POE para el descubrimiento de palabras clave utilizando WordLift Agente)
4. El gran cambio hacia una experiencia de usuario «justo a tiempo
En el diseño de UX tradicional, la información está predeterminada y puede organizarse en jerarquías, taxonomías y patrones de UI predefinidos. A medida que la IA se convierte en la interfaz del complejo mundo de la información, asistimos a un cambio de paradigma.
Las topologías de interfaz de usuario tienden a desaparecer, y la interacción entre los humanos y la IA sigue siendo predominantemente dialógica. Los flujos de trabajo asistidos «justo a tiempo» pueden ayudar al usuario a contextualizar y mejorar un flujo de trabajo.
- Hay que pensar en términos de creación de valor empresarial, centrarse en el viaje interactivo del usuario y facilitar la interacción creando una UX sobre la marcha. Las taxonomías siguen siendo un activo estratégico, pero actúan entre bastidores mientras el usuario es teletransportado de una tarea a otra, como ha descrito recientemente con brillantez Yannis Paniaras, de Microsoft.
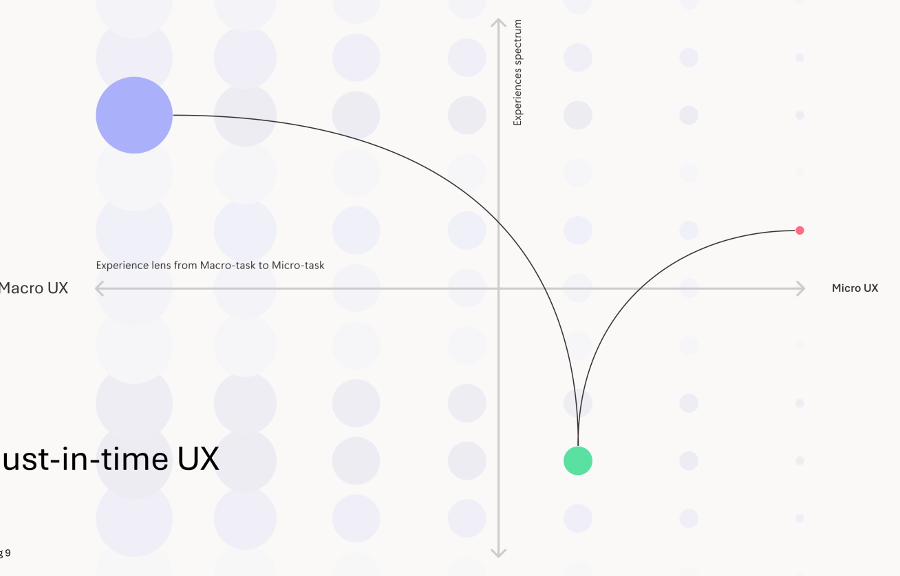
Imagen de «The Shift to Just-In-Time UX: How AI is Reshaping User Experiences» de Yannis Paniaras, agosto de 2024.
5. De los agentes a RAG (y GraphRAG) y a los informes
Dado que el usuario necesita un impacto empresarial y que la GAR es sólo una parte de la solución, la atención pasa rápidamente de las preguntas más genéricas y la respuesta a patrones de usuario a los flujos de trabajo avanzados de varios pasos.
Sin embargo, la cuestión más importante es qué resultado necesita el usuario. Si aumentamos la complejidad para captar los objetivos empresariales más elevados, no basta con, digamos, «consultar sus datos» o «chatear con su sitio web».
Un cliente quiere un informe, por ejemplo, de ¿Cuál es la coherencia temática del contenido dentro de todo el sitio web? (este es un concepto que descubrimos recientemente como SiteRadus en la filtración masiva de datos de Google), la visión general de las tendencias estacionales a través de cientos de campañas de pago, o la revisión definitiva de las oportunidades de optimización relacionadas con la optimización de Google Merchant Feed.
Debe comprender cómo funciona la empresa y por qué prestaciones pagará. ¿Qué acciones concretas podrían impulsar la empresa? ¿Qué preguntas hay que responder?
Este es el comienzo de la creación de una tremenda herramienta de información asistida por IA.
¿Cómo puede combinarse un grafo de conocimiento (KG) con una ontología para la alineación de IA, la memoria a largo plazo y la validación de contenidos?
Los tres principios rectores de la SEOntología:
- Hacer que los datos SEO sean interoperables para facilitar la creación de gráficos de conocimiento y reducir al mismo tiempo los rastreos innecesarios y el bloqueo de proveedores;
- Infundir conocimientos SEO a los agentes de IA mediante un lenguaje específico del dominio.
- Compartir conocimientos y tácticas de forma colaborativa para mejorar la capacidad de búsqueda y evitar el uso indebido de la IA generativa.
Cuando manejes al menos dos fuentes de datos en tu tarea de automatización SEO, ya verás la ventaja de utilizar SEOntology.
SEOntology como «El USB-C de los datos SEO/Crawling»
La normalización de los datos sobre activos de contenido, productos, comportamiento de búsqueda de los usuarios y perspectivas SEO es estratégica. El objetivo es tener una «representación compartida» de la Web como canal de comunicación.
Demos un paso atrás. ¿Cómo representa un motor de búsqueda una página web? Este es nuestro punto de partida. ¿Podemos normalizar la forma en que un rastreador representa los datos extraídos de una página web? ¿Cuáles son las ventajas de adoptar normas?
Casos prácticos
Integración con Botify y Dynamic Internal Linkin
En los últimos meses, hemos estado trabajando estrechamente con el equipo de Botify para crear algo emocionante: un Gráfico de Conocimiento alimentado por los datos de rastreo de Botify y mejorado por SEOntology. Esta colaboración está abriendo nuevas posibilidades para la automatización y optimización SEO.
Aprovechar los datos existentes con SEOntology
Esto es lo mejor: Si ya utilizas Botify, podemos aprovechar esa mina de oro de datos que has recopilado. No hay necesidad de rastreos adicionales o trabajo extra de su parte. Utilizamos el Botify Query Language (BQL) para extraer y transformar los datos necesarios utilizando SEOntology.
Piensa en SEOntology como un traductor universal de datos SEO. Toma la información compleja de Botify y la convierte en un formato que no sólo es legible, sino también comprensible. Esto nos permite crear un Gráfico de Conocimientos rico e interconectado, repleto de información SEO valiosa.
Lo que esto significa para usted
Una vez que tengamos este Gráfico del Conocimiento, podremos hacer cosas asombrosas:
- Datos estructurados automatizados: Podemos generar automáticamente marcado de datos estructurados para sus páginas de listado de productos (PLP). Esto ayuda a los motores de búsqueda a entender mejor su contenido, mejorando potencialmente su visibilidad en los resultados de búsqueda.
- Enlaces internos dinámicos: Aquí es donde las cosas se ponen realmente interesantes. Utilizamos los datos de Knowledge Graph para crear enlaces internos dinámicos e inteligentes en todo el sitio. Déjeme explicarle cómo funciona y por qué es tan potente.
En el diagrama siguiente, también podemos ver cómo los datos de Botify se pueden combinar con los de Google Search Console.
Aunque en la mayoría de las implementaciones, Botify ya importa estos datos en sus proyectos de rastreo, cuando este no es el caso, podemos activar una nueva solicitud de API e importar clics, impresiones y posiciones de GSC al gráfico.
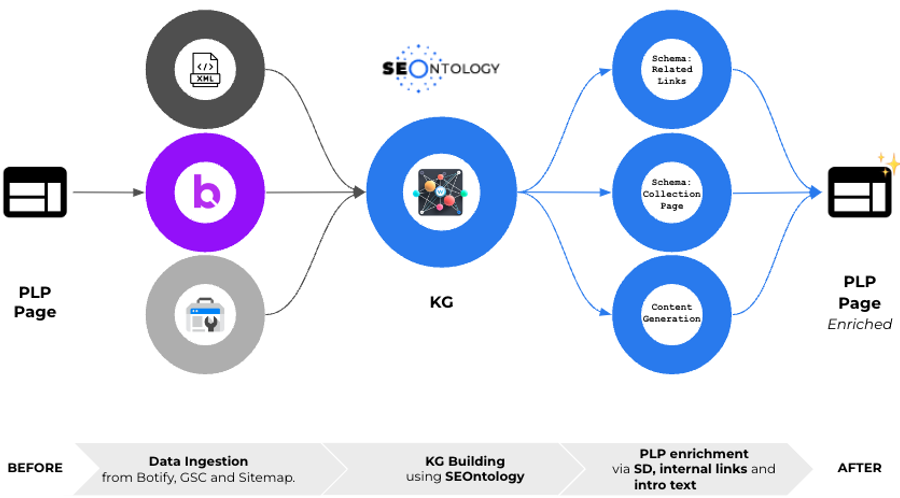
Colaboración con Advertools para la interoperabilidad de datos
Del mismo modo, colaboramos con el brillante Elias Dabbas, creador de Advertools -una biblioteca Python favorita entre los profesionales del marketing- para automatizar una amplia gama de tareas de marketing.
Nuestros esfuerzos conjuntos pretenden mejorar la interoperabilidad de los datos, permitiendo una integración y un intercambio de datos sin fisuras entre distintas plataformas y herramientas.
En el primer Cuaderno, disponible en el repositorio GitHub de SEOntology, Elias muestra cómo podemos construir atributos para la clase WebPage sin esfuerzo, incluyendo título, meta descripción, imágenes y enlaces. Esta base nos permite modelar fácilmente elementos complejos, como las estrategias de enlaces internos. Vea aquí la estructura:
- Internal_Links
- anchorTextContent
- NoFollow
- Link
También podemos añadir una bandera si la página ya está utilizando el marcado schema:
- usesSchema
Formalización de lo aprendido del análisis de los documentos de búsqueda de Google filtrados
Aunque queremos ser extremadamente conscientes a la hora de deducir tácticas o pequeños esquemas de la filtración masiva de Google, y somos muy conscientes de que Google impedirá rápidamente cualquier posible uso indebido de dicha información, existe un gran nivel de información que, basándonos en lo aprendido, puede utilizarse para mejorar la forma en que representamos el contenido web y organizamos los datos de marketing.
A pesar de estas limitaciones, la filtración ofrece información valiosa para mejorar la representación del contenido web y la organización de los datos de marketing. Para democratizar el acceso a esta información, he desarrollado una herramienta de informes de filtraciones de Google diseñada para poner esta información a disposición de los profesionales de SEO y marketing digital.
Por ejemplo, comprender el sistema de clasificación de Google y su segmentación de sitios web en varias taxonomías ha sido especialmente esclarecedor. Estas taxonomías -como «verticals4», «geo» y «products_services»- desempeñan un papel crucial en la clasificación y relevancia de las búsquedas, cada una con atributos únicos que influyen en cómo se perciben y clasifican los sitios web y los contenidos en los resultados de búsqueda.
Aprovechando la SEOntología, podemos adoptar algunos de estos atributos para mejorar la representación del sitio web.
Ahora, párate un segundo e imagina transformar los complejos datos SEO que manejas a diario a través de herramientas como Moz, Ahrefs, Screaming Frog, Semrush, y muchas otras en un gráfico interactivo. Ahora, imagina un Agente Autónomo de IA, como el Agente WordLift, a tu lado.
Este agente emplea IA neurosimbólica, un enfoque de vanguardia que combina capacidades de aprendizaje neural con razonamiento simbólico, para automatizar tareas SEO como la creación y actualización de enlaces internos. Esto agiliza el flujo de trabajo e introduce un nivel de precisión y eficiencia hasta ahora inalcanzable.
SEOntology sirve como columna vertebral para esta visión, proporcionando un marco estructurado que permite el intercambio y la reutilización de datos SEO a través de diferentes plataformas y herramientas. Al estandarizar cómo se representan e interconectan los datos SEO, SEOntology garantiza que los valiosos conocimientos derivados de una herramienta puedan aplicarse y aprovecharse fácilmente en otras. Por ejemplo, los datos sobre el rendimiento de palabras clave de SEMrush podría informar a las estrategias de optimización de contenidos en WordLift, todo dentro de un entorno unificado e interoperable. Esto no sólo maximiza la utilidad de los datos existentes, sino que también acelera los procesos de automatización y optimización que son cruciales para un marketing eficaz.
Infundir conocimientos SEO en los agentes de IA
A medida que desarrollamos un nuevo enfoque de SEO y marketing digital, SEOntology sirve como nuestro lenguaje específico de dominio (DSL) para codificar las habilidades de SEO en agentes de IA. Veamos un ejemplo práctico de cómo funciona.
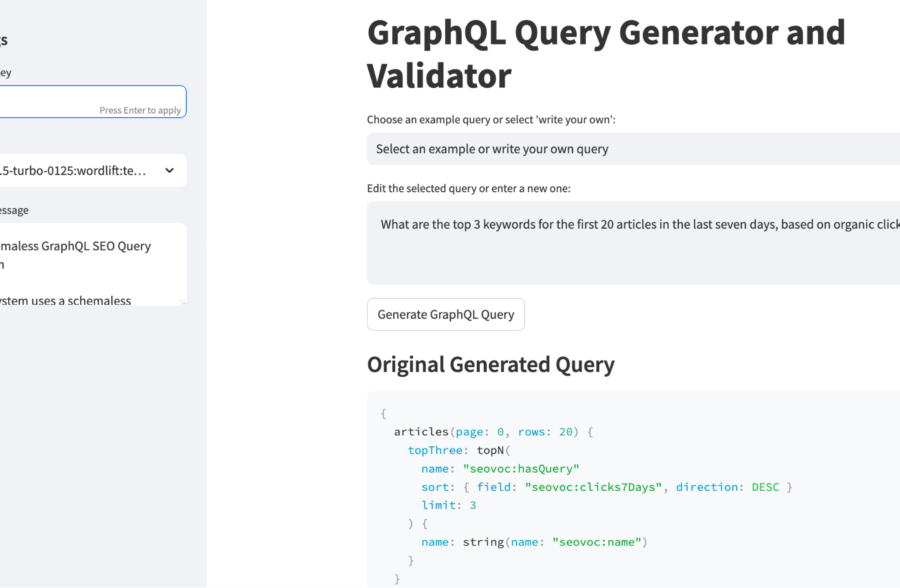
Captura de pantalla de WordLift, agosto de 2024
Hemos desarrollado un sistema que hace que los agentes de IA conozcan el rendimiento de las búsquedas orgánicas de un sitio web, lo que permite un nuevo tipo de interacción entre los profesionales de SEO y la IA. He aquí cómo funciona el prototipo:
Componentes del sistema
- Gráfico de conocimiento: Almacena los datos de Google Search Console (GSC), codificados con SEOntology.
- LLM: traduce las consultas en lenguaje natural a GraphQL y analiza los datos.
- Agente de IA: Proporciona información basada en los datos analizados.
Interacción Persona-Agente
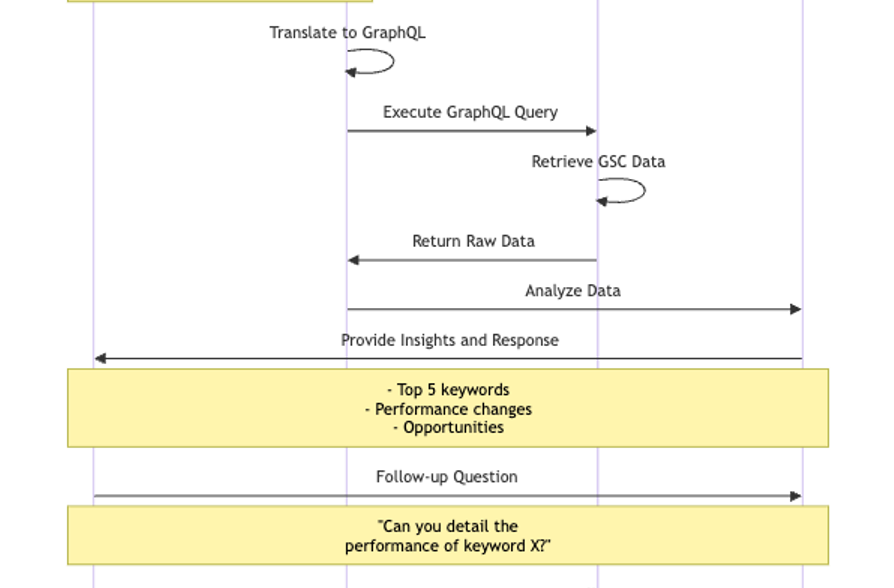
Imagen del autor, agosto de 2024
El diagrama ilustra el flujo de una interacción típica. Esto es lo que hace que este enfoque sea potente:
- Interfaz de lenguaje natural: Los profesionales de SEO pueden hacer preguntas en lenguaje sencillo sin necesidad de construir consultas complejas.
- Comprensión contextual: El LLM comprende los conceptos SEO, lo que permite matizar las consultas y las respuestas.
- Análisis perspicaz: El agente de IA no se limita a recuperar datos, sino que proporciona información práctica, como:
- Identifying top-performing keywords.
- Highlighting significant performance changes.
- Suggesting optimization opportunities.
- Exploración interactiva: Los usuarios pueden hacer preguntas de seguimiento, lo que permite una exploración dinámica del rendimiento SEO.
Mediante la codificación de los conocimientos de SEO a través de SEOntology y la integración de los datos de rendimiento, estamos creando agentes de IA que pueden proporcionar ayuda contextual y matizada en las tareas de SEO. Este enfoque acorta la distancia entre los datos brutos y la información práctica, haciendo que el análisis SEO avanzado sea más accesible para los profesionales de todos los niveles.
Este ejemplo ilustra cómo una ontología como SEOntology puede ayudarnos a crear herramientas SEO auténticas que automatizan tareas complejas al tiempo que mantienen la supervisión humana y garantizan resultados de calidad. Es un vistazo al futuro del SEO, donde la IA aumenta la experiencia humana en lugar de sustituirla.
Human-In-The-Loop (HTIL) e intercambio colaborativo de conocimientos
Seamos claros: aunque la IA está revolucionando el SEO y la búsqueda, los humanos son el corazón de nuestra industria. A medida que nos adentramos en el mundo de la SEOntología y los flujos de trabajo asistidos por IA, es fundamental entender que Human-in-the-Loop (HITL) no es solo un complemento extravagante, sino la base de todo lo que estamos construyendo.
La esencia de la creación de SEOntology es transferir nuestra experiencia colectiva en SEO a las máquinas, garantizando al mismo tiempo que nosotros, como humanos, sigamos ocupando firmemente el asiento del conductor. No se trata de entregar las llaves a la IA, sino de enseñarle a ser el copiloto definitivo en nuestro viaje SEO.
IA dirigida por humanos: el elemento humano irremplazable
SEOntology es más que un marco técnico – es un catalizador para el intercambio de conocimientos de colaboración que hace hincapié en el potencial humano en SEO. Nuestro compromiso se extiende más allá del código y los algoritmos para nutrir las habilidades y ampliar las capacidades de la nueva generación de vendedores y profesionales de SEO.
¿Por qué? Porque el verdadero poder de la IA en SEO se desbloquea con la visión humana, las diversas perspectivas y la experiencia del mundo real. Tras años trabajando con flujos de trabajo de IA, me he dado cuenta de que el SEO agentivo se centra fundamentalmente en el ser humano. No sustituimos la experiencia, sino que la ampliamos.
Proporcionamos resultados más eficientes y fiables combinando tecnología punta con creatividad humana, intuición y juicio ético. Este enfoque genera confianza entre los clientes de nuestro sector y en Internet.
Aquí es donde los humanos siguen siendo insustituibles:
- Comprensión de las necesidades empresariales: La IA puede hacer números, pero no puede sustituir a la comprensión matizada de los objetivos empresariales que aportan los profesionales de SEO experimentados. Necesitamos expertos que puedan traducir los objetivos del cliente en estrategias de SEO viables.
- Identificar las limitaciones del cliente: Cada negocio es único, con sus limitaciones y oportunidades. Se necesita perspicacia humana para navegar por estas restricciones y desarrollar enfoques SEO a medida que funcionen dentro de los parámetros del mundo real.
- Desarrollo de algoritmos de vanguardia: Los algoritmos que impulsan nuestras herramientas de IA no surgen de la nada. Necesitamos mentes brillantes para desarrollar algoritmos de vanguardia, aprender de las aportaciones humanas y mejorar continuamente.
- Ingeniería de sistemas robustos: Detrás de cada herramienta de IA que funciona correctamente hay un equipo de ingenieros de software que garantizan que nuestros sistemas sean rápidos, seguros y fiables. Esta experiencia humana hace que nuestros asistentes de IA funcionen como máquinas bien engrasadas.
- Pasión por una Web mejor: En el corazón de SEO está el compromiso de hacer de la web un lugar mejor. Necesitamos personas que compartan la visión de Tim Berners-Lee, personas apasionadas por el desarrollo de la web de datos y la mejora del ecosistema digital para todos.
- Alineación y resistencia de la comunidad: Necesitamos unirnos para analizar el comportamiento de los gigantes de las búsquedas y desarrollar estrategias resistentes. Se trata de resolver nuestros problemas de forma innovadora como individuos y como fuerza colectiva. Esto es lo que siempre me ha gustado del sector del SEO.
Ampliar el alcance de la SEOntología
Mientras seguimos desarrollando la SEOntología, no actuamos de forma aislada. Por el contrario, nos basamos en las normas existentes y las ampliamos, en particular Schema.org, y seguimos el exitoso modelo del GS1 Web Vocabulary.
La SEOntología como extensión de Schema.org
Schema.org se ha convertido en el estándar de facto para los datos estructurados en la web, proporcionando un vocabulario compartido que los webmasters pueden utilizar para marcar sus páginas.
Sin embargo, aunque Schema.org cubre una amplia gama de conceptos, no profundiza en los elementos específicos de SEO. Aquí es donde entra SEOntology.
Una extensión de Schema.org, como SEOntology, es esencialmente un vocabulario complementario que añade nuevos tipos, propiedades y relaciones al vocabulario básico de Schema.org.
Esto nos permite mantener la compatibilidad con las implementaciones existentes de Schema.org al tiempo que introducimos conceptos específicos de SEO no contemplados en el vocabulario básico.
Aprender del vocabulario web GS1
El GS1 Web Vocabulary ofrece un gran modelo para crear una extensión de éxito que interactúe a la perfección con Schema.org. GS1, una organización global que desarrolla y mantiene los estándares de la cadena de suministro, creó su Vocabulario Web para extender Schema.org para casos de uso de comercio electrónico e información de productos.
El GS1 Web Vocabulary demuestra, incluso recientemente, cómo las extensiones específicas de la industria pueden influir e interactuar con el marcado de Schema:
- Impacto en el mundo real: La propiedad https://schema.org/Certification, ahora adoptada oficialmente por Google, se originó a partir de https://www.gs1.org/voc/CertificationDetails de GS1. Esto demuestra cómo las extensiones pueden impulsar la evolución de Schema.org y las capacidades de los motores de búsqueda.
Queremos seguir un enfoque similar para ampliar Schema.org y convertirnos en el vocabulario estándar para las aplicaciones relacionadas con SEO, influyendo potencialmente en las futuras capacidades de los motores de búsqueda, los flujos de trabajo impulsados por IA y las prácticas de SEO.
Al igual que GS1 definió su espacio de nombres (gs1:) al hacer referencia a los términos de Schema, nosotros hemos definido nuestro espacio de nombres (seovoc:) e integramos las clases dentro de la jerarquía de Schema.org cuando es posible.
El futuro de la SEOntología
SEOntology es algo más que un marco teórico; es una herramienta práctica diseñada para capacitar a los profesionales de SEO y a los creadores de herramientas en un ecosistema cada vez más impulsado por la IA.
A continuación te explicamos cómo puedes participar y beneficiarte de SEOntology.
Si está desarrollando herramientas SEO:
- Interoperabilidad de datos: Implementa SEOntology para exportar e importar datos en un formato estandarizado. Esto garantiza que sus herramientas puedan interactuar fácilmente con otros sistemas compatibles con SEOntology.
- Datos listos para la IA: Al estructurar tus datos de acuerdo con SEOntology, los estás haciendo más accesibles para automatizaciones y análisis impulsados por IA.
Si eres un profesional de SEO:
- Contribuir al desarrollo: Al igual que con Schema.org, puedes contribuir a la evolución de SEOntology. Visita su repositorio en GitHub:
Plantee cuestiones sobre nuevos conceptos o propiedades que considere que deberían incluirse.
Proponer cambios en las definiciones existentes.
Participar en debates sobre la futura dirección de la SEOntología.
- Impleméntelo en su trabajo: Empieza a utilizar los conceptos de SEOntology en tus datos estructurados.
Confiamos en el código abierto
SEOntology es un esfuerzo de código abierto, siguiendo los pasos de proyectos de éxito como Schema.org y otros vocabularios enlazados compartidos.
Todas las discusiones y decisiones serán públicas, garantizando que la comunidad tenga voz y voto en la dirección de SEOntology. A medida que vayamos ganando adeptos, crearemos un comité para dirigir su desarrollo y compartir actualizaciones periódicas.
Conclusión y trabajo futuro
El futuro del marketing es humano, no sustituido por la IA. La SEOntología no es una palabra de moda más, sino un paso hacia ese futuro. El SEO es estratégico para el desarrollo de prácticas de marketing agentivo.
El SEO ya no se trata de clasificaciones; se trata de crear contenido inteligente y adaptable y diálogos fructíferos con nuestros grupos de interés a través de varios canales. Estandarizar los datos y las prácticas de SEO es estratégico para construir un futuro sostenible e invertir en una IA responsable.
¿Estás preparado para unirte a esta revolución?
Hay tres principios rectores detrás del trabajo de SEOntology que debemos dejar claros al lector:
- As AI needs semantic data, we need to make SEO data interoperable, facilitating the creation of knowledge graphs for everyone. SEOntology is the USB-C of SEO/crawling data. Standardizing data about content assets and products and how people find content, products, and information in general is important. This is the first objective. Here, we have two practical use cases. We have a connector for WordLift that gets crawl data from the Botify crawler and helps you jump-start a KG that uses SEOntology as a data model. We are also working with Advertools, an open-source crawler and SEO tool, to make data interoperable with SEOntology;
- As we progress with the development of a new agentic way of doing SEO and digital marketing, we want to infuse the know-how of SEO using SEOntology, a domain-specific language to infuse the SEO mindset to SEO agents (or multi-agent systems like Agent WordLift). In this context, the skill required to create dynamic internal links is encoded as nodes in a knowledge graph, and opportunities become triggers to activate workflows.
- We expect to work with human-in-the-loop HITL, meaning that the ontology will become a way to collaboratively share knowledge and tactics that help improve findability and prevent the misuse of Generative AI that is polluting the Web today.
Resumen del proyecto
Este trabajo sobre SEOntology es fruto de la colaboración. Hago extensivo mi más sincero agradecimiento al equipo de WordLift, especialmente a su director técnico, David Riccitelli. También agradezco a nuestros clientes su dedicación a la innovación en SEO a través de los gráficos de conocimiento. Un agradecimiento especial a Milos Jovanovik y Emilia Gjorgjevska por su experiencia crítica. Por último, agradezco a la comunidad SEO y al equipo editorial de SEJ su apoyo para compartir este trabajo.